PDF(5834 KB)
PDF(5834 KB)

Wetland area segmentation based on multi-scale features dual-coding Transformer
ZHAO Yuankun, HU Chunhua
Journal of Nanjing Forestry University (Natural Sciences Edition) ›› 2026, Vol. 50 ›› Issue (3) : 229-238.
PDF(5834 KB)
 PDF(5834 KB)
PDF(5834 KB)
Wetland area segmentation based on multi-scale features dual-coding Transformer
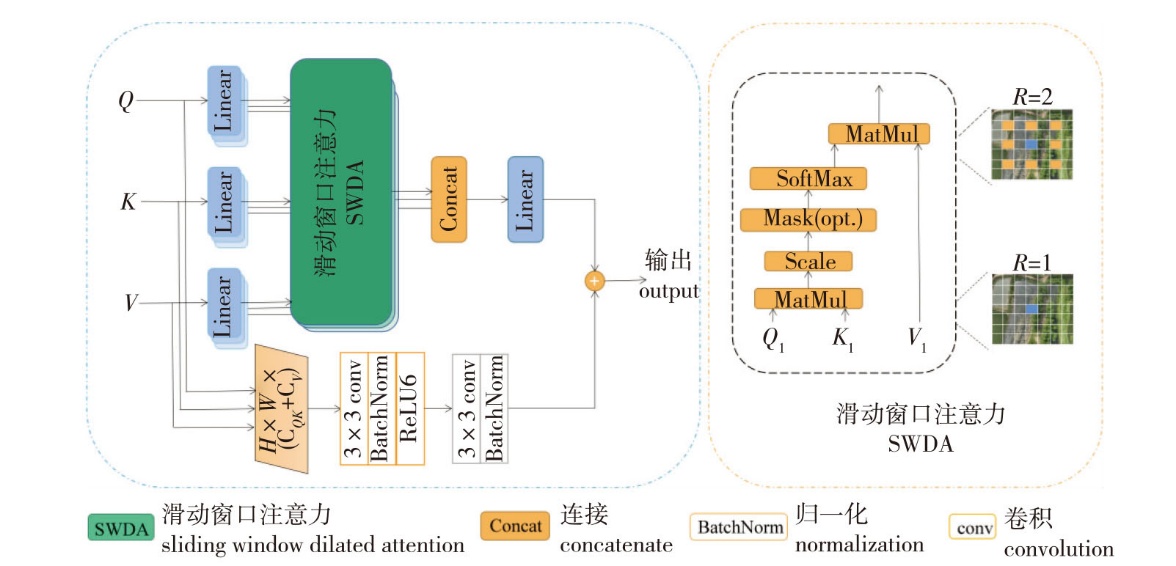
【Objective】The precise delineation of wetland ecosystems through unmanned aerial vehicle(UAV)imagery analysis is essential for ecological resource management,particularly in environments with intricate land-cover patterns and dynamic seasonal variations. To overcome persistent limitations in existing semantic segmentation frameworks—specifically,feature degradation during hierarchical downsampling and insufficient discriminative power for semantically overlapping categories(e.g.,aquaculture ponds vs. natural water bodies)—this study introduces MfdFormer,a dual-encoder Transformer-based network optimized for UAV-borne wetland remote sensing. The architecture strategically reconciles computational efficiency with high-precision segmentation requirements,addressing critical operational constraints in real-time environmental monitoring scenarios.【Method】Methodological advancements center on a hierarchically structured dual-encoding paradigm. The primary encoder employs pyramidal spatial reduction modules with depthwise separable convolutions,systematically compressing input resolutions through four stages while preserving discriminative edge features. Complementing this,the secondary encoder deploys a novel information completes multiscale void attention(ICMVA)mechanism,which synergizes localized window-based self-attention with adaptive semantic gap-filling operations. This dual-path configuration enables concurrent capture of fine-grain textures and long-range contextual dependencies,particularly critical for distinguishing spectrally similar vegetation types. The decoding phase incorporates the parameter-decoupling micro-decoders that progressively merge multi-scale features through the channel-wise attention gating,followed by cross-level feature recalibration using 3×3 depthwise convolution. A semantic fusion module is incorporated into the decoding architecture to significantly improve the discriminative capability for morphologically analogous categories.【Result】The systematic evaluation protocol implemented on the Hongze Lake wetland dataset in Jiangsu Province—comprising 1 872 precisely annotated UAV-captured images categorized into five ecologically distinct land cover classes—provides conclusive evidence of MfdFormer's segmentation efficacy. Quantitative analysis reveals the architecture achieves an exact mean intersection-over-union(mIoU)score of 88.07% across all semantic categories,with particularly notable performance in woodland ecosystem delineation attaining 93.13% class-specific IoU. Comparative assessments against established benchmarks under standardized testing conditions demonstrate consistent superiority,surpassing Topformer's segmentation accuracy by 0.68 percentage points and HRNet's baseline performance by 0.76 percentage points in the comprehensive mIoU metrics. Cross-domain validation procedures executed on the UAVid urban remote sensing benchmark further substantiate the model's generalizability,yielding an mIoU of 1.81 percentage points higher than the Topformer's equivalent performance metric. Controlled ablation experiments quantitatively isolate the functional contribution of the interleaved contextual multi-view attention(ICMVA)mechanism through systematic component substitution. Replacement of ICMVA with standard windowed attention architectures results in measurable performance degradation,most acutely observed in texture-heterogeneous regions characterized by mixed vegetation canopies and fragmented hydrological formations,where IoU scores decrease by precisely 1.16 percentage points.【Conclusion】The rational omission of non-critical information in images,combined with randomized multi-positional local feature extraction through iterative minimal sampling,enables effective reconstruction of global contextual information,thereby enhancing the determinacy and accuracy of segmentation boundaries while reducing computational resource demands. For categories exhibiting substantial intra-class shape variance,strategically reducing detailed feature extraction mitigates the network overfitting risks. Multi-dimensional feature fusion demonstrates significant potential in recognizing complex wetland categories,as the integration of heterogeneous feature dimensions facilitates macro-scale object comprehension,ultimately improving the segmentation capability for UAV-acquired wetland imagery. The proposed MfdFormer architecture effectively balances segmentation precision and computational efficiency through its dual-branch feature extraction mechanism and multi-scale semantic integration strategy. Experimental results across heterogeneous datasets validate its robustness in handling complex wetland landscapes characterized by irregular boundaries and high intra-class variance,establishing practical value for large-scale wetland resource monitoring.
semantic segmentation / Hongze Lake wetland / area segmentation / dual coding / sliding window attention
| [1] |
崔丽娟, 雷茵茹, 张曼胤, 等. 小微湿地研究综述:定义、类型及生态系统服务[J]. 生态学报, 2021, 41(5):2077-2085.
|
| [2] |
杨楠, 王卫星, 赵祥模. 基于Retinex和改进的最小生成树分割提取模糊航空图像中的河流[J]. 山东农业大学学报(自然科学版), 2017, 48(6):890-896.
|
| [3] |
赵庆展, 江萍, 王学文, 等. 基于无人机高光谱遥感影像的防护林树种分类[J]. 农业机械学报, 2021, 52(11):190-199.
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
林洁如, 朱洪前, 杨国, 等. 基于改进DeepLabv3+的林木图像分割方法[J]. 林业工程学报, 2024, 9(3): 119-126.
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
何自芬, 史本杰, 张印辉, 等. 多注意力融合的环高原湖泊遥感影像分割[J]. 电子学报, 2023, 51(4):885-895.
|
| [14] |
|
| [15] |
|
| [16] |
朱小亮, 张海明, 侍猛, 等. 洪泽湖水质现状研究[J]. 当代化工研究, 2023(5):83-85.
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
/
| 〈 |
|
〉 |